k8s에서 가장 까다로운 부분 중 하나는 네트워크라고 생각한다.
이미 구글링 하면 여러 다른 사이트에서 이 글보다 훨씬 쉽고 자세하게 설명해준 글들이 많다.
그래서 나는 굳이 모든 통신의 경우를 다 정리하진 않는 대신, pod-to-service의 통신과정과 실제 환경에서 룰을 확인해볼 것이다.
pod-to-service를 알면 그 밑단의 pod-to-pod 혹은 다른 노드 간의 pod-to-pod 통신도 쉽게 이해할 수 있기 때문이다.
구조

위 그림은 node X의 pod A가 service를 통해 node Y의 pod B로 통신하는 과정을 보여주고 있다.
이 시나리오에 따라 차례차례 설명하도록 하겠다.
① pod A가 DNS 서비스로 콜
pod A가 서비스(DNS)로 콜을 보내면, 각 컨테이너의 /etc/resolv.conf에 쓰여있는 규칙대로 coredns에게 해석을 요청한다.
coredns는 해당 서비스의 cluster ip(10.96.xx.xx)를 알려준다. 이제부터 이 ip를 이용해 node Y의 pod B를 찾으려 한다. veth0은 서비스의 cluster ip가 어디 있는지 모르므로, 상위 네트워크 인터페이스로 패킷을 올려 보낸다.
하지만 노드와 pod의 네트워크 대역은 다르다. 따라서 노드와 pod이 통신을 하기 위해서는 두 네트워크 대역을 연결해주는 무언가가 필요하다. 그 설정을 도와주는 것이 CNI(Container Network Interface)라는 모듈이다. CNI는 k8s의 pod 통신을 위해 네트워크 인터페이스를 설정해주는 모듈이다.
그림에서는 생략했지만, veth(virtual ethernet)은 쌍(pair)으로 존재한다. 즉, 노드에 pod 3개가 떠있다면 총 3개의 veth 인터페이스가 존재한다. 여기서 cbr0은 pod 네트워크 인터페이스에서 일종의 (veth들의)게이트웨이 역할을 한다.
실제 노드에서 iptables를 입력하면 위와 같은 결과를 볼 수 있다. 해당 노드에 떠있는 pod들의 veth의 pair관계인 인터페이스 들이다.
사진에서 보이는 tunl0가 그림에서 cbr0에 해당한다. 이 노드의 pod들은 모르는 IP가 있으면 tunl0로 패킷을 보내게 된다. 설치한 CNI 모듈에 따라 인터페이스 이름은 다를 수 있다.
② cbr0 → eth0로 가는 패킷을 낚아채서 룰에 의해 NAT하는 netfilter
pod-to-service 통신에서 가장 중요한 부분이다.
원래대로라면 cbr0도 서비스 ip를 모르므로 상위 인터페이스로 보내게 된다. 하지만 chain rule을 통해 패킷의 목적지를 포워딩해주게 되는데, 이 chain rule이 정의되어 있는 곳이 netfilter이다. netfilter는 리눅스 커널의 기능 중 하나로 rule-based 패킷 처리 엔진이다. kernel space에 위치하여 오고 가는 모든 패킷을 관찰하며 rule에 따라 패킷을 포워딩해준다. 그리고 이 netfilter에 규칙을 수정하는 것이 kube-proxy라는 k8s의 pod이다.
구체적으로는 netfilter가 서비스 IP(10.96.xx.xx)로 들어오는 패킷을 chain rule에 의해 실제 pod IP(10.244.2.6)로 DNAT 해주는 것이다. kube-proxy는 단지 netfilter 규칙을 적절하게 수정하기만 한다. (k8s 1.2 하위 버전에서는 kube-proxy가 직접 라우팅 했다.)
NAT는 Network Address Translation의 약자로, 말 그대로 네트워크의 주소를 바꿔준다고 이해하면 된다. SNAT와 DNAT가 있는데 각각 SourceNAT와 DestinationNAT를 뜻하며, 출발지 혹은 도착지의 주소를 바꿔준다는 뜻이다.
참고로 리눅스의 user space에서 실행되는 iptables라는 인터페이스가 netfilter를 이용하여 chain rule에 의해 패킷을 포워딩한다. 따라서, 아래와 같이 iptables 명령어를 통해 확인해볼 수 있다.
위 스크린샷은 특정 서비스만 grep 해서 확인해본 결과이다.
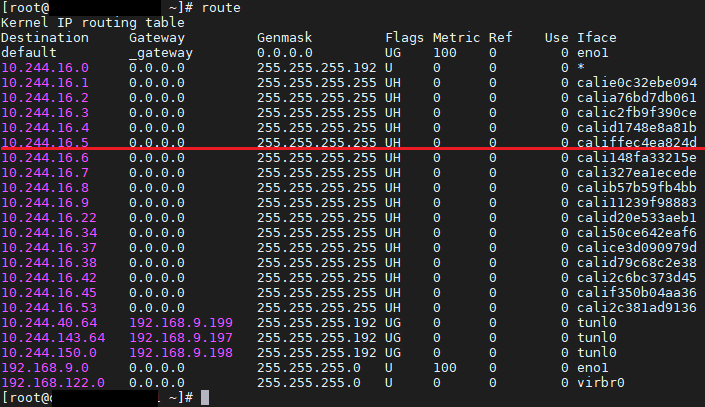
10.96.157.10이라는 서비스의 cluster ip 가 KUBE-SVC-WVB4SFQYY2BFP54D 룰에 의해 KUBE-SEP-AFKM5H6SWI6XO6EE로 포워딩되고, KUBE-SEP-AFKM5H6SWI6XO6EE는 실제 pod ip인 10.244.16.5로 포워딩되는 것을 확인할 수 있다.
즉, 10.96.157.10 → KUBE-SVC-WVB4SFQYY2BFP54D → KUBE-SEP-AFKM5H6SWI6XO6EE → 10.244.16.5의 과정을 거쳐서 실제 pod ip로 포워딩되는 것이다!
③, ④ : 라우팅 테이블에 따라 라우팅
②에서 실제 pod ip를 알게 된 이후부터는 쉽다. 각 호스트의 라우팅 테이블에 적혀있는 규칙에 따라 라우팅해준다. node Y의 pod B의 ip는 10.244.2.6이므로, 그림 상에서 두 번째 규칙을 따라서 192.168.9.4의 ip를 가진 노드로 패킷이 가게 된다.
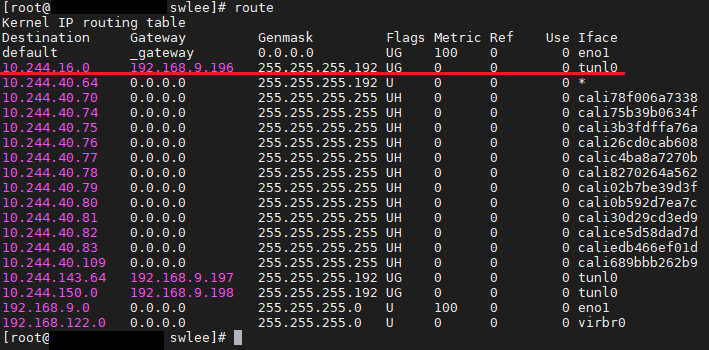
②에서의 예시에 나온 pod ip는 10.244.16.5 이므로 192.168.9.196의 ip를 가진 노드로 패킷이 전달될 것이다.
그림 상으로는 라우팅 테이블이 하나있는 것 처럼 표현했지만, 위의 실제 route 명령어 처럼 각 호스트마다 테이블을 가지고 있다.
⑤ : 도착지의 netfilter가 cbr1로 포워딩
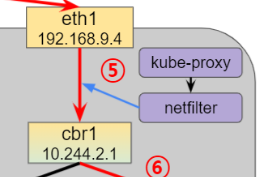
도착지의 노드에서도 역시 netfilter가 오고 가는 패킷을 관리하고 있다. ②에서와 마찬가지로 netfilter는 규칙에 따라 eth1로 들어온 패킷을 cbr1로 포워딩해준다.
⑥ : 실제 pod으로 패킷 전송

cbr1과 veth1은 같은 네트워크 대역을 공유하고 있다. cbr1은 10.244.2.x 대역의 게이트웨이 역할로서, 10.244.2.6이 어디에 존재하는지를 알고 있으므로, cbr1에서 veth1로 패킷을 넘겨준다.
정확히는 veth1의 pair 인터페이스를 거쳐서 넘어가지만 생략했다.
정리
여기까지 pod-to-service의 통신 과정을 정리해보았다. netfilter가 service ip를 pod ip로 바꿔주는 부분만 제외하면 pod-to-pod 통신과 다를 게 없다. 이론적인 정리뿐만 아니라 실제로 명령어를 통해 룰을 확인해보니 머리에 더 잘 남는 것 같다. 이제 k8s에서 네트워크 문제가 생기면 어느 부분을 봐야 할지 감이 생긴 듯 하다.
참고 사이트
https://coffeewhale.com/k8s/network/2019/04/19/k8s-network-01/
======== (수정 내역)
2022.08.09
각 노드에 라우팅 테이블이 존재하기 때문에, 게이트웨이는 알맞지 않다고 판단하여 ③,④ 내용에서 게이트웨이 내용을 뺐습니다.
잘못된 내용이 있으면 댓글로 달아주세요!!
'공부 > Kubernetes' 카테고리의 다른 글
| 첫 PR 성공적으로 merge!! (0) | 2021.09.24 |
|---|---|
| 첫 PR 날려봤다 (0) | 2021.09.16 |
| docker image 경량화 build 하기 (0) | 2021.09.10 |
| Kubernetes operator 메커니즘 (5) | 2021.08.31 |
| Kubernetes Audit (감사로그) (3) | 2021.08.09 |